
万族各有托,孤云独无依
Linux 三剑客是 grep , sed , awk 三者的简称,熟练使用这三个工具可以提高运维效率。
三者的功能都是处理文本,但侧重点各不相同,其中属awk功能最强大,但也最复杂。grep更适合单纯的查找或匹配文本,sed更适合编辑匹配到的文本,awk更适合格式化文本,对文本进行较复杂格式处理。
Linux 三剑客以正则表达式作为基础,熟练掌握好正则表达式是使用Linux三剑客的前提。在掌握好正则表达式后,将具体讲解三剑客的用法。
1. 正则表达式
正则表达式(regular expression)描述了一种字符串匹配的模式,可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
在Linux系统中,支持两种正则表达式,分别是标准正则表达式和扩展正则表达式。
1.1 元字符
| 字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置 |
| $ | 匹配输入字符串的结尾位置 |
| * | 匹配前面的子表达式零次或多次 |
| + | 匹配前面的子表达式一次或多次 |
| ? | 匹配前面的子表达式零次或一次 |
| {n} | 匹配n次 |
| {n,} | 匹配至少n次 |
| {n,m} | 匹配n次到m次 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配 |
| . | 匹配除换行符 \n 之外的任何单字符 |
| [xyz] | 匹配 […] 中的所有字符 |
| [^xyz] | 匹配除了 […] 中字符的所有字符 |
| [a-z] | 匹配[a-z]区间内的字符,即所有小写字母 |
| \d | 匹配一个数字字符。等价于 [0-9] |
| \D | 匹配一个非数字字符。等价于 [^0-9] |
| \w | 匹配字母、数字、下划线。等价于 [A-Za-z0-9_] |
| \W | 匹配非字母、数字、下划线 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v] |
| \S | 匹配任何非空白字符 |
| [\s\S] | 匹配所有。\s 是匹配所有空白符, 包括换行, \S 非空白符, 包括换行。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK |
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符 |
| \num | num 是一个正整数。对所获取的匹配的引用。例如,’(.)\1’ 匹配两个连续的相同字符。 |
1.2 修饰符
| 字符 | 描述 |
|---|---|
| i | 不区分大小写 (ignore) |
| g | 全局匹配 (global) |
| m | 多行匹配 (multi line) |
| s | 使特殊字符圆点 . 中包含换行符 \n |
1.3 字符簇
PHP的正则表达式有一些内置的通用字符簇,列表如下:
| 字符簇 | 描述 |
|---|---|
| [[:alpha:]] | 任何字母 |
| [[:digit:]] | 任何数字 |
| [[:alnum:]] | 任何字母和数字 |
| [[:space:]] | 任何空白字符 |
| [[:upper:]] | 任何大写字母 |
| [[:lower:]] | 任何小写字母 |
| [[:punct:]] | 任何标点符号 |
| [[:xdigit:]] | 任何16进制的数字,相当于[0-9a-fA-F] |
1.4 贪婪和非贪婪
* 和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只要在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配。
?当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。
例如以下这个字符串:
1 | <h1>今天我的爱情结束了</h1> |
贪婪模式:/<.*>/ 将匹配整个字符串
而非贪婪模式:/<.*?>/ 只匹配到第一个<h1>
1.5 ?=、?<=、?!、?<!
1 | exp1(?=exp2):查找 exp2 前面的 exp1 |
举例:
1 | /meidou(?=[\d+])/g 匹配数字前面的meidou字符串 |
2. grep
grep 命令用于查找文件里符合条件的字符串,并把匹配的行打印出来,将匹配到的标红。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
2.1 命令格式
1 | grep [option] pattern file |
2.2 命令参数
1 | -A<显示行数>:除了显示符合样式的那一行之外,还显示该行之后的内容。 |
2.3 示例
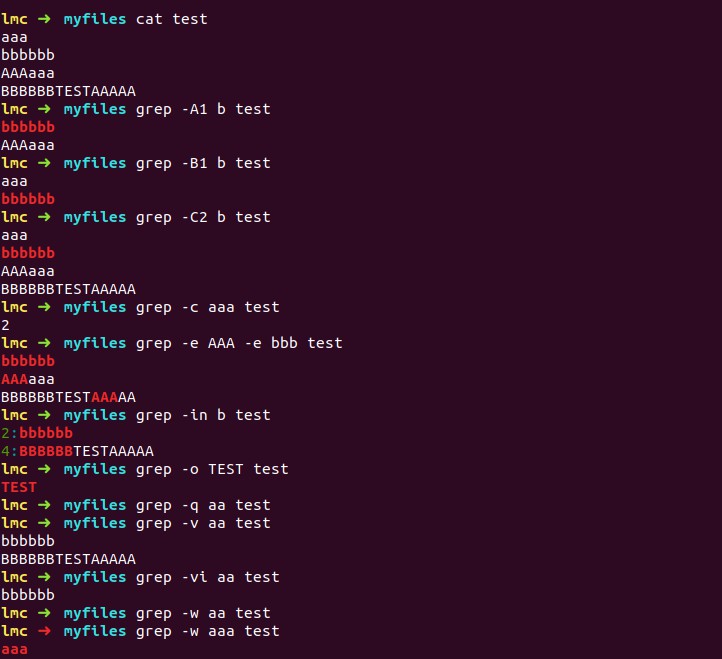
3. sed
Sed 命令主要用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。
sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(patternspace ),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下行,执行下一个循环。如果没有使诸如‘D’ 的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出或-i。
功能:主要用来自动编辑一个或多个文件, 简化对文件的反复操作
sed 可依照脚本的指令来处理、编辑文本文件。
3.1 命令格式
1 | sed [options][动作][文件] |
3.2 命令参数
1 | -e<script> 或 - -expression=<script>:多点编辑,以选项中指定的script来处理输入的文本文件 |
3.3 命令动作
1 | a :追加,在指定行后面追加文本,支持使用\n实现多行追加 |
3.4 示例
1 | d: 删除 |
4. awk
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。
之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
awk是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内建的功能,比如数组、函数等,这是它和C语言的相同之处,灵活性是awk最大的优势。
4.1 命令格式
1 | awk [option] 'PATTERN{ACTION STATEMENTS}' FILE |
4.2 命令选项
常用命令选项option:
1 | -F:指名输入字段的分隔符 |
4.3 awk内置变量
awk常用内置变量:
1 | FS 设置输入域分隔符,默认空白字符,等价于命令行 -F选项 |
4.4 示例
1 | # 统计/etc/passwd:文件名,每行的行号,每行的列数,对应的完整行内容: |